Glossary
Browse the IADC Lexicon alphabetically or by category. Get comprehensive definitions of drilling industry terms.
Oil & Gas Drilling Glossary - IADCLexicon.org
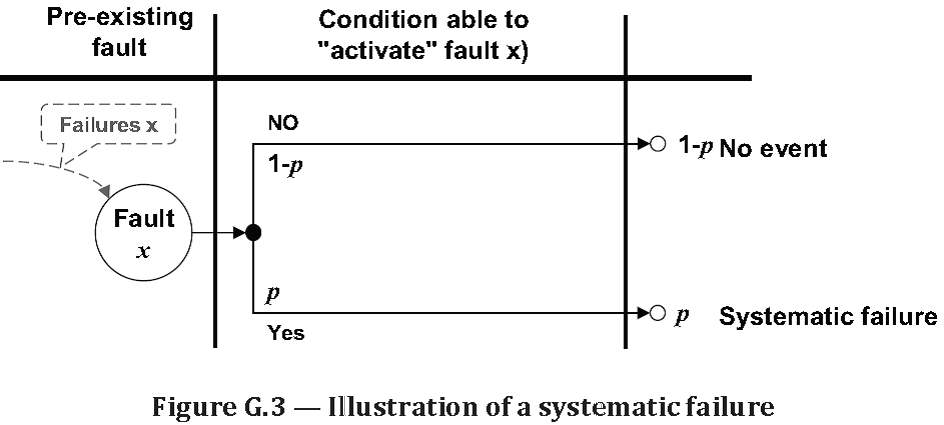 Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards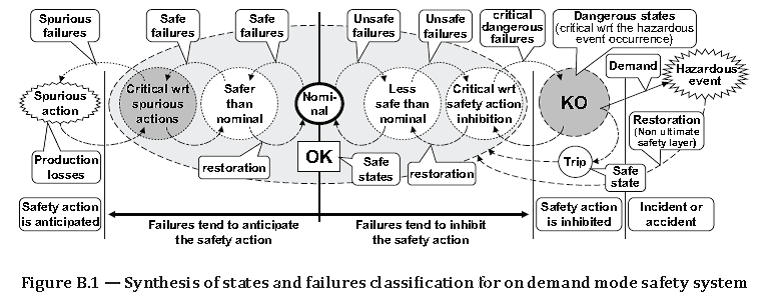 Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards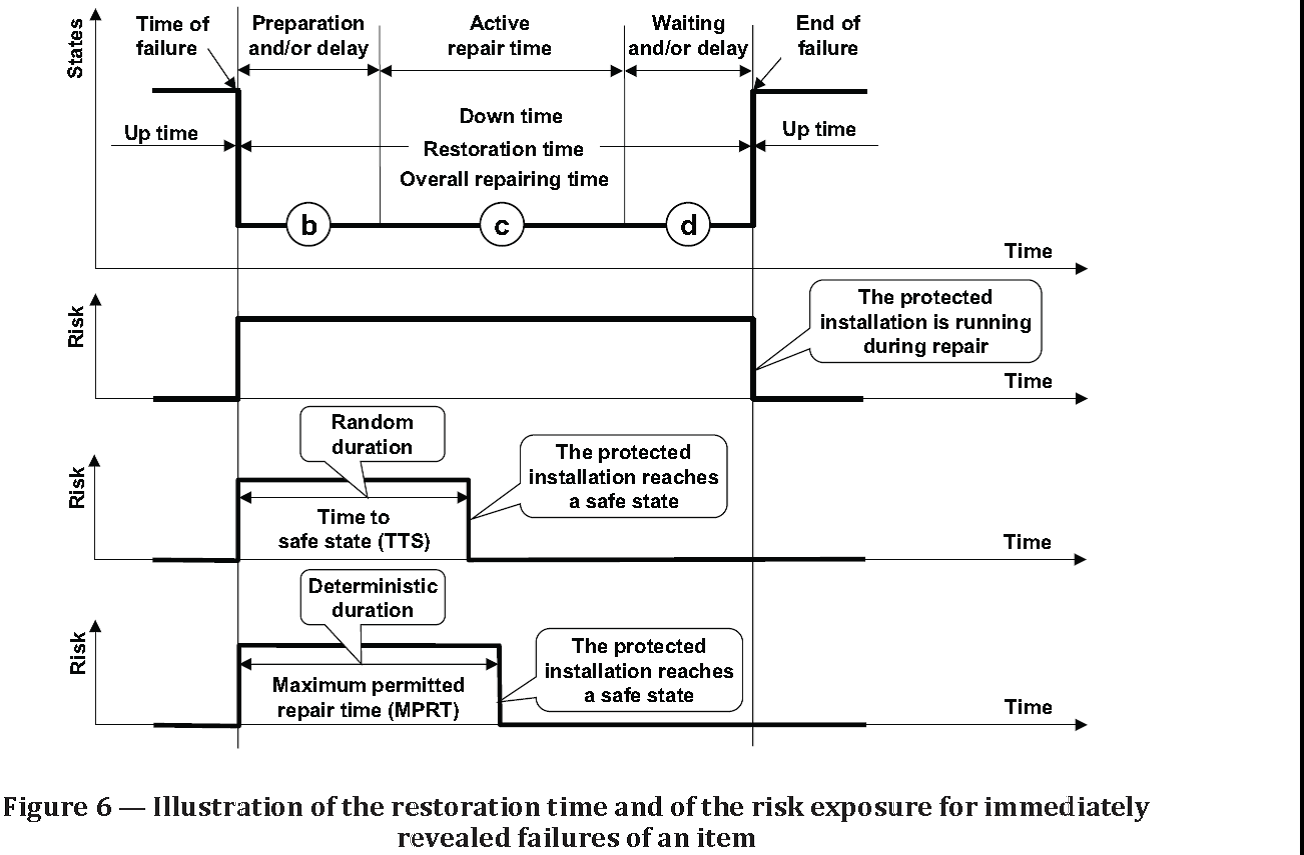
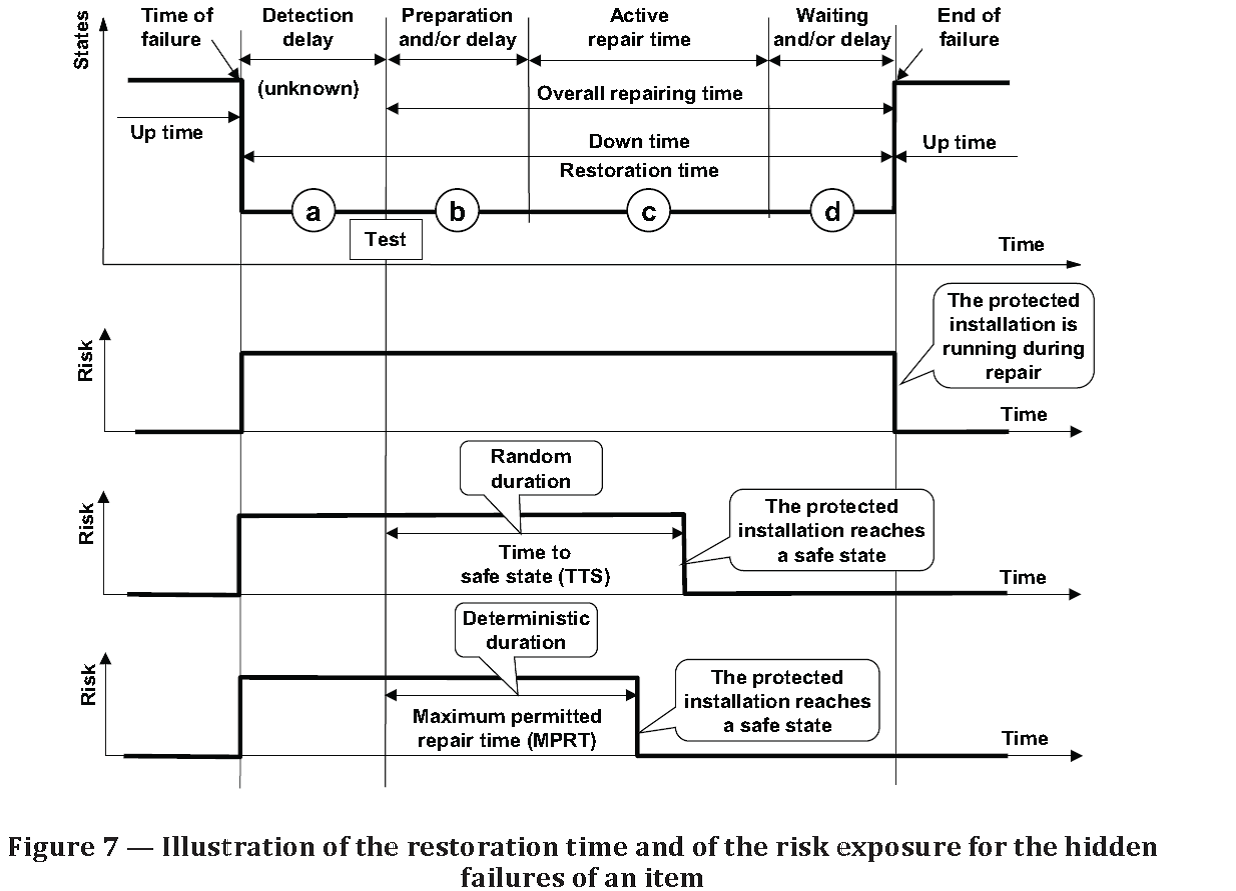
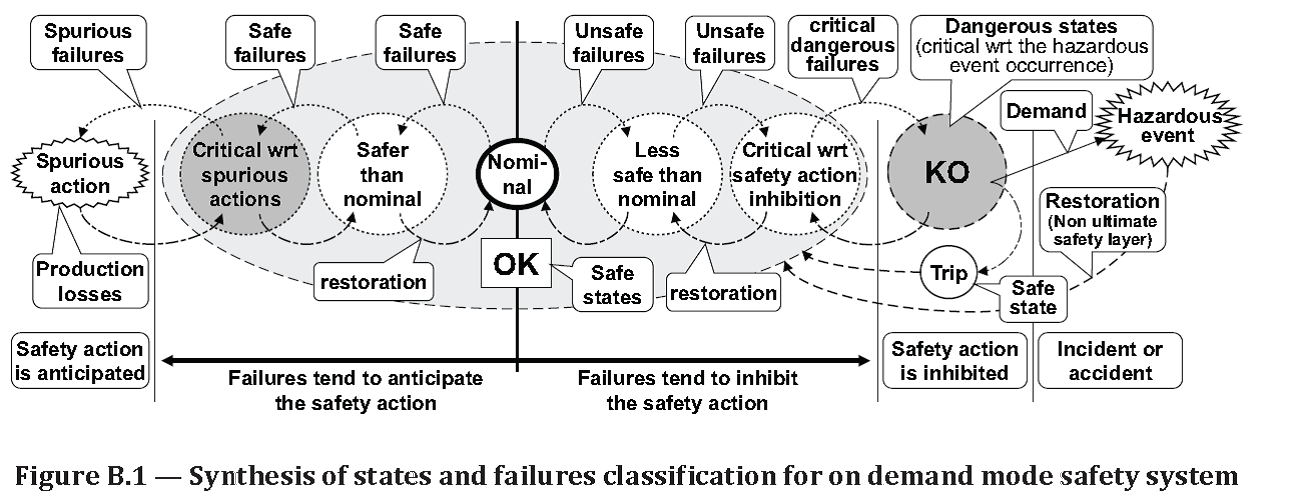 Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards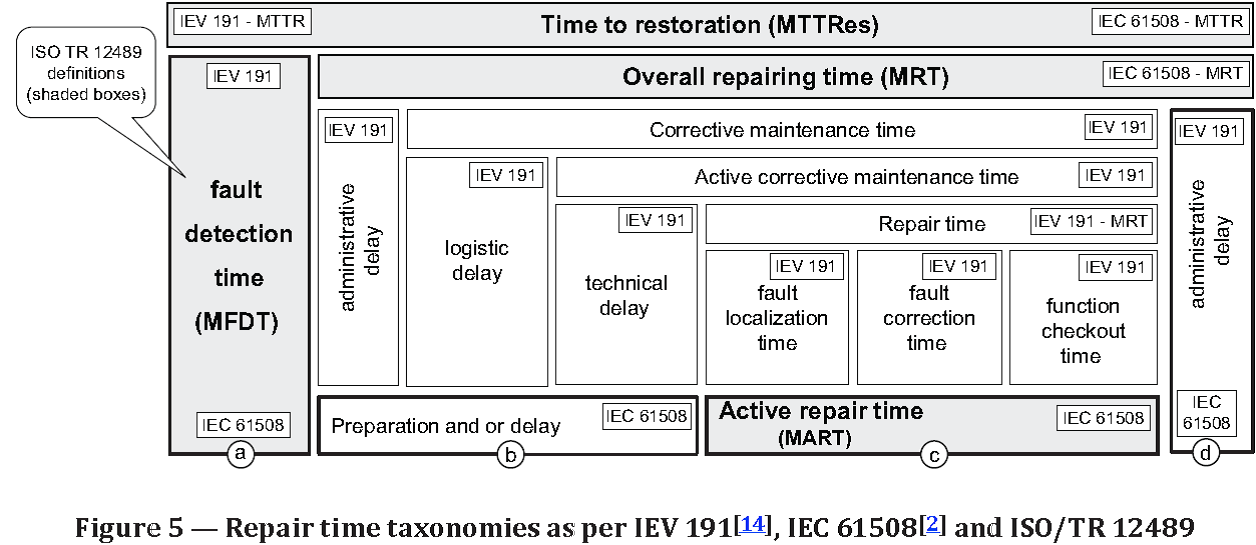 Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
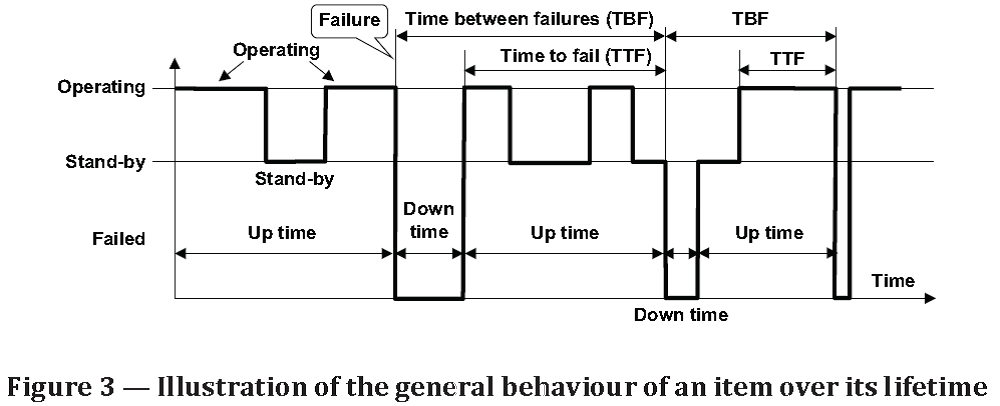 Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
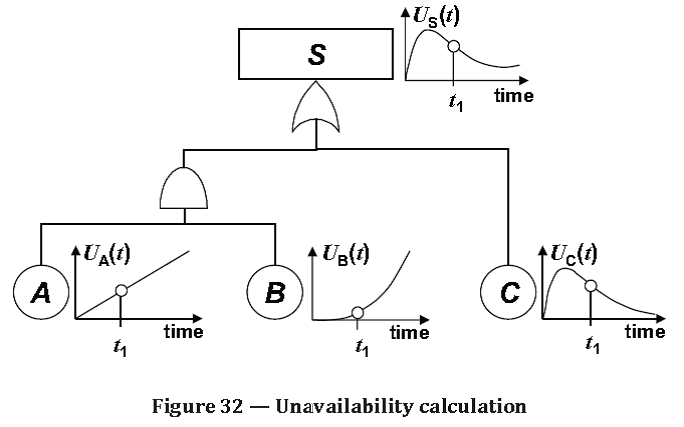
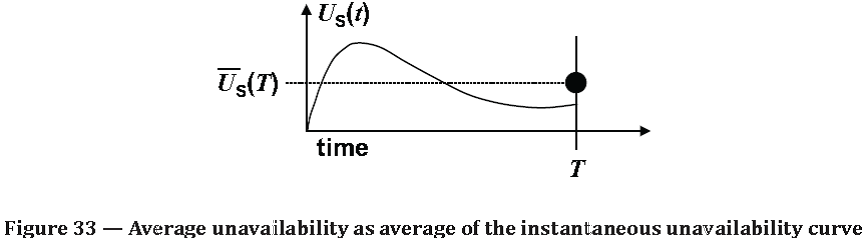
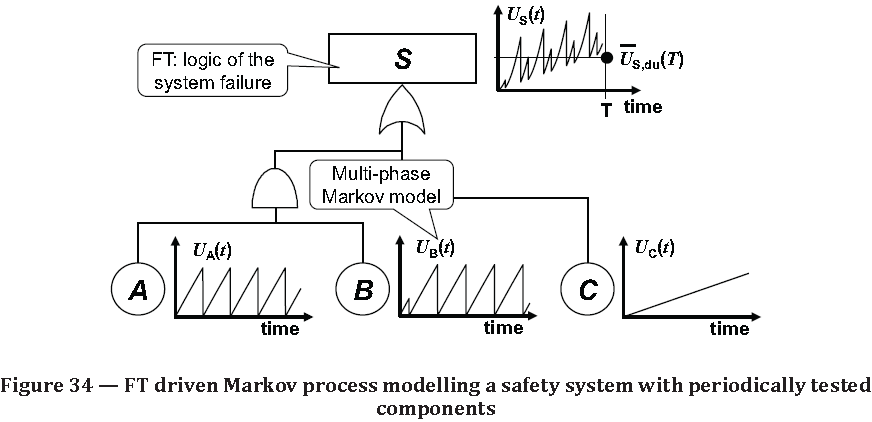 Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards
Source: ISO/TR 12489:2013(E) Reliability modelling and calculation of safety systems. Global Standards